
Suppose you want to uniformly sample from the interior of a circle of unit radius, in other words, from a unit disk. The “gut feel” way is to pick a random angle, 
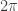


Oops. Something’s gone wrong! The density of points in the center of the disk are higher than at the edges, and, in fact, the density goes down as the edge is approached.
Now, there are approximate workarounds involving more computation. Rejection sampling is one that comes to mind. In that case, instead of drawing values for parameters of a polar distribution, the idea is to generate from a 2-by-2 square centered on the origin, and then reject instances outside of a circle with unit radius, also centered at the origin. But this is wasteful and really not necessary. The alternative is simple.
The key observation is that for any randomly chosen radius 


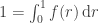
![1 = \int_{0}^{1} f(r)\,\mathrm{d}r = \int_{0}^{1} k r\,\mathrm{d}r = [\frac{k}{2} r^2]_{0}^{1} = \frac{k}{2}](https://s0.wp.com/latex.php?latex=1+%3D+%5Cint_%7B0%7D%5E%7B1%7D+f%28r%29%5C%2C%5Cmathrm%7Bd%7Dr+%3D++%5Cint_%7B0%7D%5E%7B1%7D+k+r%5C%2C%5Cmathrm%7Bd%7Dr+%3D+%5B%5Cfrac%7Bk%7D%7B2%7D+r%5E2%5D_%7B0%7D%5E%7B1%7D++%3D+%5Cfrac%7Bk%7D%7B2%7D&bg=ffffff&fg=333333&s=0&c=20201002)

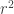
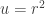


Okay, so what does this have to do with the Internet?
A lot of present day assessment of the Internet is done using two basic tools, ping and traceroute. Both have as a key element the idea that a packet is sent towards some target. An engineering feature of such packets on the Internet is that they contain a piece of control information called time to live or TTL. This is woven into the fundamental fabric of the Internet so packets don’t just flood it and make it useless. The basic idea is that when a node on the Internet receives a packet, and it is not intended for it, it decrements the TTL by one, overwriting that field with the decremented value, and then sends the revised packet on its merry way towards the target. Should the decrement result in a TTL value of zero, however, rather than sending the packet on, the node crafts a letter to the original sender of the packet saying in effect “You did not affix sufficient postage”. That letter is called a TTL-exceeded ICMP message, and it contains, among other things, the address of the node at which the TTL-exceeded event occurred. That’s good because that tells the sender (us!) how far the packet went and that’s exactly how ping and traceroute are used explore the Internet … They don’t know these addresses, so to explore what addresses are out there and who’s connected to whom, traceroute explores by sending packets with successively greater TTLs out towards the target, until it is reached.
The transition of a packet from one node to another along its way to a target is called a hop. Traceroutes are devices for elucidating the hops taken to arrive at a target.
Now, a ping is like a traceroute except that it involves sending a packet to specific recipients who will respond back with the time the packet was received. This lets engineers do things like measure latency. But, as you might imagine, ping packets also have TTLs and in fact you can think of the interior of the loop of a traceroute as involving doing a ping.
If an engineer wants to explore the structure of the Internet, traceroutes are good for getting basic structure. (There are offline sources as well, not important for this post.) But if the engineer wants to obtain a representative set of addresses across the Internet for a study, say, a representative sample of all addresses within some number of hops of an origin or vantage point, the arguments about the disk above say that tabulating all the addresses seen within that number of hops and their frequency is going to be a biased representation of this number of addresses. If all the addresses at a TTL value of 
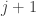
So, the argument above suggests a remedy. Rather than doing or keeping addresses associated with every TTL, the addresses associated with TTLs up to some maximum (say 40) should be retained so the TTLs are picked if they equal the rounded value of 
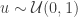
In fact, there are advantages to incorporating this into the sampling plan. Nodes and paths leading to them excessively close to the vantage point are oversampled in the original plan, and unnecessarily so. This costs in unwarranted network load, and in complaints of abuse by network nearest neighbors. If the sampling plan can incorporate the square root factor, then the effort and load applied to that section of the network can be reallocated more usefully, at addresses farther away, with no additional cost.
See? Math rules.




