
(Updated 4th December 2018.)
There are many devices available for making numerical calculations fast. Modern datasets and computational problems apply stylized architectures, and use approaches to problems including special algorithms for just calculating dominant eigenvectors or using non-classical statistical mechanisms like shrinkage to estimate correlation matrices well. But sometimes it’s simpler than that.
In particular, some calculations can be preconditioned. What’s done varies with the problem, but often there is a one-time investment in creating a numerical data structure which is then used repeatedly to obtain fast performance of some important kind.
This post is a re-presentation of a technique I devised in 1984 for finding sums of contiguous submatrices of a given matrix in constant time. The same technique can be used to calculate moments of such submatrices, in order to support estimating statistical moments or moments of inertia, but I won’t address those in this post. Studies of these problems, given this technique, can imagine how that might be done. If there’s an interest and a need, with comments or email, I’ll some day post algorithm and code for doing moments.

The Algorithm
Assume there is a square matrix, 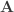



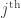

To form



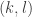
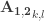
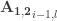




Because there are only two sums involved in the calculation of the sum of any submatrix, the algorithm does this in constant time, irrespective of the sizes of the submatrices. There are dynamic range tricks that can be applied should the sums of values in the preconditioned matrix get very large in magnitude.
The code is available in the Google Drive folder for such things.
###############################################################################################
# This section of code up to the next group of #### marks is owned and copyrighted by #
# Jan Galkowski, who has placed it in the public domain, available for any purpose by anyone. #
###############################################################################################
fastMeansFastMomentsPrecondition<- function(X)
{
# # (From Jan Galkowski, ``Fast means, fast moments'', 1984,
# # IBM Federal Systems Division, Owego, NY. Released into the public domain, 1994.)
stopifnot( is.matrix(X) )
M<- nrow(X)
stopifnot( M == ncol(X) )
AX1<- apply(X=X, MARGIN=2, FUN=cumsum)
# AX2<- t(apply(X=X, MARGIN=1, FUN=cumsum))
AX12<- t(apply(X=AX1, MARGIN=1, FUN=cumsum))
return(AX12)
}
fastMeansFastMomentsBlock<- function(P, iUL, jUL, iLR, jLR)
{
# # (From Jan Galkowski, ``Fast means, fast moments'', 1984,
# # IBM Federal Systems Division, Owego, NY. Released into the public domain, 1994.)
#
# P is the preconditioned AX12 from above.
#
stopifnot( is.matrix(P) )
M<- nrow(P)
stopifnot( M == ncol(P) )
stopifnot( (1 <= iUL) && (iUL <= M) )
stopifnot( (1 <= jUL) && (jUL <= M) )
stopifnot( (1 <= iLR) && (iLR <= M) )
stopifnot( (1 <= jLR) && (jLR <= M) )
#
iUL1<- iUL-1
jUL1<- jUL-1
iLR1<- iLR-1
jLR1<- jLR-1
#
if (0 == iUL1)
{
W.AL<- 0
W.A<- 0
if (0 == jUL1)
{
W.L<- 0
} else
{
W.L<- P[iLR,jUL1]
}
} else if (0 == jUL1)
{
W.AL<- 0
W.L<- 0
if (0 == iUL1)
{
W.A<- 0
} else
{
W.A<- P[iUL1,jLR]
}
} else
{
W.AL<- P[iUL1,jUL1]
W.A<- P[iUL1,jLR]
W.L<- P[iLR,jUL1]
}
#
W<- P[iLR,jLR] + W.AL - W.A - W.L
#
return(W)
}
# Self-test FMFM ...
cat("Fast means, fast moments self-test ...\n")
Z<- matrix(round(runif(100, min=1, max=100)), 10, 10)
Z.P<- fastMeansFastMomentsPrecondition(Z)
stopifnot( sum(Z[1:4,1:5]) == fastMeansFastMomentsBlock(Z.P, 1, 1, 4, 5) )
stopifnot( sum(Z[8:10, 8:9]) == fastMeansFastMomentsBlock(Z.P, 8, 8, 10, 9) )
stopifnot( sum(Z[4:7, 3:5]) == fastMeansFastMomentsBlock(Z.P, 4, 3, 7, 5) )
rm(list=c("Z", "Z.P"))
cat("... Self-test completed.\n")
###############################################################################################
# End of public domain code. #
###############################################################################################
randomizeSeed<- function()
{
#set.seed(31415)
# Futz with the random seed
E<- proc.time()["elapsed"]
names(E)<- NULL
rf<- E - trunc(E)
set.seed(round(10000*rf))
# rm(list=c("E", "rf"))
return( sample.int(2000000, size=sample.int(2000, size=1), replace=TRUE)[1] )
}
wonkyRandom<- randomizeSeed()
So, there’s a little story of how this came to be public domain.
I used to work for IBM Federal Systems Division, in Owego, NY. I worked as both a software engineer and later, in a much more fun role, as a test engineer specializing in hardware-software which did quantitative calculations. IBM, as is common, had a strong intellectual property protection policy and framework.
Well, in 1994, Loral bought Federal Systems from IBM. As former employees, we were encouraged to join the new organization, but, naturally, were asked to sign a bunch of paperwork. To my personal surprise, there was nothing in the paperwork which had to do with IBM’s rights to intellectual property we might have originated or held. All they wanted was for us to sign onto the new division, part of Loral.
Before I signed, therefore, I approached corporate counsel and pointed out there was no restriction on intellectually property or constraints upon its disposition. They, interested in making the transition happen, said “Yes”. I went off and prepared a document of all the material and algorithms and such which I thought I had developed while on IBM time in which they hadn’t expressed any interest, including offers to put it up for patenting or whatever. It was a reasonably thick document, maybe 100 pages, and I still have a copy. I asked the attorneys to sign over the intellectual property rights of these to me, and they did. It was witnessed. I had made my coming to Loral contingent upon doing this, and they seemed happy to do it. I signed once I had this in hand. I still have a copy.
I did not know at the time, but Loral’s interest was in purchasing Federal Systems, and they had every intention of “flipping it”, as one might a house, to another buyer in a short time, and they apparently didn’t care about this.
But, as a result, this algorithm, for fast means and fast moments, which I had developed in 1984 while doing some image processing work, became mine. And I have always treated it as public domain, available to anyone for any purpose. And, here, with this post, I put it out there for your public use, for any purpose whatsoever, without constraints. Very open source. Commercial or otherwise.
Enjoy.
It would be nice to credit me, but you don’t have to do that.





Pingback: Towards the end of 2018, Newtonmas, and on commenting standards that have excelled | Hypergeometric
Neat! I’ve seen similar ideas for linear arrays, but haven’t ever thought about doing it for 2- (or higher! This generalizes.) dimensional things.
Thanks, Greg!