Consider trying to determine the length of a straight stick. Instead of the measurement errors being clustered about zero, suppose the errors are known to be always positive, that is, no measurement ever underestimates the length of the stick. Such a stick is shown in the figure below.

Basically, what’s observed is  , with
, with 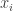 being a random variable such that
being a random variable such that  .
.
This problem is actually equivalent to a class of others. For example, the figure below shows one. In this case there are actually  straight sticks, each of which have a length
straight sticks, each of which have a length  and “errors in measurement”
and “errors in measurement” 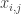 . But what’s observed is a single length,
. But what’s observed is a single length,  , as
, as

Here the overall length  and what was called the added random variable before is
and what was called the added random variable before is  .
.

How would this be done. Well,  is constant so if, say, it was known how the measurement errors were distributed, then obtaining is straightforward.
is constant so if, say, it was known how the measurement errors were distributed, then obtaining is straightforward.
Suppose, for instance, that the are distributed as a Poisson. Then, because the mean of a Poisson is equal to its variance, and because, for any random variable,  , and constant,
, and constant,  ,
,
![\text{VAR}[c + X] = \text{VAR}[X]](https://s0.wp.com/latex.php?latex=%5Ctext%7BVAR%7D%5Bc+%2B+X%5D+%3D+%5Ctext%7BVAR%7D%5BX%5D&bg=ffffff&fg=333333&s=0&c=20201002)
estimating amounts to:
- calculating the mean of
- calculating the variance of
- taking their difference, or
![E[y_{i}] - \text{VAR}[y_{i}]](https://s0.wp.com/latex.php?latex=E%5By_%7Bi%7D%5D+-+%5Ctext%7BVAR%7D%5By_%7Bi%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
In some applications, the “randomness” of the may be a descriptive approximation. For example, in percolation networks, the path length of a water particle through a closely packed and already wet section of sand of differing grain size can be thought of as it making a number of choices of turns about impeding grains, the net being that these appear as random errors of positive size, even if they are, in each instance specific and unchanging, even if not knowable. Such a path is shown in the figure below.

These are interesting mathematical problems, with applications in hydrology, geophysics, epidemiology, and sociology.
What happens if the errors are not Poisson? Well, different models for the errors could be used — and even a mix of models — but, in general, such errors could be multi-modal

In that case, a non-parametric model is desirable. This can be combined in a Bayesian scheme using a stick-breaking prior. (See also.) The length of the stick, , cannot be larger than the minimum length observed,  . Thus, as a candidate for , pick a value,
. Thus, as a candidate for , pick a value, 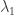 , as a sample of a uniform random number on the interval from zero to . Then, as a candidate for the mean of the measurement noise, pick a value,
, as a sample of a uniform random number on the interval from zero to . Then, as a candidate for the mean of the measurement noise, pick a value,  , as a sample of a uniform random number on the interval from zero to
, as a sample of a uniform random number on the interval from zero to  . Then observe the variance of the as a Gamma distribution with some reasonable shape. This is a Bayesian hierarchical model.
. Then observe the variance of the as a Gamma distribution with some reasonable shape. This is a Bayesian hierarchical model.
To get specific,


![\text{VAR}[y_{i}] \sim \mathsf{Ga}(\kappa, \frac{\lambda_{2}}{\kappa})](https://s0.wp.com/latex.php?latex=%5Ctext%7BVAR%7D%5By_%7Bi%7D%5D+%5Csim+%5Cmathsf%7BGa%7D%28%5Ckappa%2C+%5Cfrac%7B%5Clambda_%7B2%7D%7D%7B%5Ckappa%7D%29&bg=ffffff&fg=333333&s=0&c=20201002)

Here the Gamma density,  has a shape of
has a shape of  and a scale of
and a scale of  . Sometimes, as in JAGS and BUGS, Gamma densities are parameterized in terms of a rate instead of a scale, which is the reciprocal of the scale or, here,
. Sometimes, as in JAGS and BUGS, Gamma densities are parameterized in terms of a rate instead of a scale, which is the reciprocal of the scale or, here,  . This can be seen as a set-up for a stochastic search.
. This can be seen as a set-up for a stochastic search.
How well does it work?
Well, first here is the BUGS code:
var m, n, y[n,m], mu[2,m],
ymin[m], ymax[m], yvar[m],
kappa;
model
{
# PRIORS
kappa ~ dunif(2, 100)
for (j in 1:m)
{
# mu[1,:] is the estimate of the minimum
# mu[2,:] is the mean of added noise
mu[1,j] ~ dunif(0, ymin[j])
mu[2,j] ~ dunif(0, (ymax[j] - mu[1,j]))
yvar[j] ~ dgamma( kappa, kappa/mu[2,j] )
}
# MODEL
for (j in 1:m)
{
for (i in 1:n)
{
y[i,j] ~ dnorm((mu[1,j] + mu[2,j]), 100)
}
}
#inits# .RNG.name, .RNG.seed
#monitor# mu, kappa
#data# n, m, y, ymin, ymax, yvar
}
The tests reported here ran 3 independent cases, so  .
.  denotes the number of observations per case, a value which will be indicated when the results are reported below.
denotes the number of observations per case, a value which will be indicated when the results are reported below.  denotes the observations, rows and
denotes the observations, rows and  columns.
columns.  ,
,  , and
, and  are each vectors of length m containing the minimum, maximum, and variance for each of the m cases. Different kinds of positive error densities were used for a simple evaluation. In all cases the “true lengths” of the sticks were 13, 5, and 21, respectively, for cases 1, 2, and 3.
are each vectors of length m containing the minimum, maximum, and variance for each of the m cases. Different kinds of positive error densities were used for a simple evaluation. In all cases the “true lengths” of the sticks were 13, 5, and 21, respectively, for cases 1, 2, and 3.
The first errors added were Poisson, each having a mean and variance of 2. There were  observations generated for each of the 3 cases. The means of the 3 sets of 20 were 15.6, 6.55, and 23.25, respectively, and their variances were 3.515789474, 1.944736842, and 1.039473684. (The excess precision is deliberate, for purposes of documentation.) The recipe given above for Poisson data produces estimates of the lengths as 12.08421053, 4.605263158, and 22.21052632, compared to the actuals of 13, 5, and 21. The stick-breaking Bayesian procedure above produced estimates of 11.5131224643, 4.2231132697, and 20.688221523. This was run using JAGS using 10,000 adaptation steps, 200,000 burn-in steps, and 3 million primary steps, thinning 1-in-100 for 30,000 samples, effectively. Gelman-Rubin multivariate PSRF was 1.02, and all variables had PSRF values under 1.05. (This run took 3 minutes using 3 of 4 cores on a 3.2 GHz 64-bit workstation, with no memory constraints.) The common value had a mean of 25.9.
observations generated for each of the 3 cases. The means of the 3 sets of 20 were 15.6, 6.55, and 23.25, respectively, and their variances were 3.515789474, 1.944736842, and 1.039473684. (The excess precision is deliberate, for purposes of documentation.) The recipe given above for Poisson data produces estimates of the lengths as 12.08421053, 4.605263158, and 22.21052632, compared to the actuals of 13, 5, and 21. The stick-breaking Bayesian procedure above produced estimates of 11.5131224643, 4.2231132697, and 20.688221523. This was run using JAGS using 10,000 adaptation steps, 200,000 burn-in steps, and 3 million primary steps, thinning 1-in-100 for 30,000 samples, effectively. Gelman-Rubin multivariate PSRF was 1.02, and all variables had PSRF values under 1.05. (This run took 3 minutes using 3 of 4 cores on a 3.2 GHz 64-bit workstation, with no memory constraints.) The common value had a mean of 25.9.
The next errors added were 4 times a Beta random variable having both its shape parameters equaling 2. That looks like the purple line in

It’s mean is 2 and its maximum is 4. 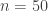 observations per case were used. The stick-breaking Bayesian procedure produced estimates of 12.8382797743, 5.0637212340, and 20.2159258567, respectively for the cases where the actual lengths are 13, 5, and 21. Again, JAGS was used, with 10,000 adaptation steps, 200,000 burn-in steps, and 3 million primary, thinning 1-in-100. The multivariate PSRF was worse than in the Poisson case, begin 1.15. Convergence was poorer for the first of the three cases than in the others. (This run took 6.6 minutes on the same hardware as above.) The common value had a mean of 11.0.
observations per case were used. The stick-breaking Bayesian procedure produced estimates of 12.8382797743, 5.0637212340, and 20.2159258567, respectively for the cases where the actual lengths are 13, 5, and 21. Again, JAGS was used, with 10,000 adaptation steps, 200,000 burn-in steps, and 3 million primary, thinning 1-in-100. The multivariate PSRF was worse than in the Poisson case, begin 1.15. Convergence was poorer for the first of the three cases than in the others. (This run took 6.6 minutes on the same hardware as above.) The common value had a mean of 11.0.
The next errors added were half-Gaussians, of mean 4 and standard deviation 1. In other words, Gaussian errors were generated, but their absolute values were taken before adding them to the true stick lengths.  observations were used in each case. The stick-breaking Bayesian procedure produced estimates of 14.0260363155, 5.4179282352, and 20.370834914, respectively. Note the corresponding minimum values of the populations were 15.5700347670, 6.6854522364, and 23.0599805370. 10,000 adaptation steps were used, and 200,000 burn-in steps. In this case 9 million primary steps were taking, again thinning 1-in-100. (This took 11.2 minutes.) The multivariate PSRF was 1.15, with the first and third cases showing some convergence stress. The common value had a mean of 3.2.
observations were used in each case. The stick-breaking Bayesian procedure produced estimates of 14.0260363155, 5.4179282352, and 20.370834914, respectively. Note the corresponding minimum values of the populations were 15.5700347670, 6.6854522364, and 23.0599805370. 10,000 adaptation steps were used, and 200,000 burn-in steps. In this case 9 million primary steps were taking, again thinning 1-in-100. (This took 11.2 minutes.) The multivariate PSRF was 1.15, with the first and third cases showing some convergence stress. The common value had a mean of 3.2.
Finally, Gamma errors were added, having a mean of 2 and a variance of 0.25. $n = 50$ observations were generated. The stick-breaking Bayesian procedure yielded estimates of 13.7986086833, 5.9373813183, and 22.1958578133, respectively, for the cases of lengths 13, 5, and 21. There were 10,000 adaptation steps, 200,000 burn-in steps, and 3 million primary steps, with 1-in-100 thinning. Multivariate PSRF was unity, and all of the parameters had PSRF values below 1.05. (This took 6.3 minutes.) The common value had a mean of 11.0.
As is typical for non-parametric procedures, these results suggest Bayesian non-parametric procedures are robust for this kind of estimation, but need more data. Still, they are less susceptible to risks of model mismatches.
Related










