
Part 1 of this series introduced the idea of ctDNA and its use for detecting cancers or their resurgence, and proposed a scheme whereby relative concentrations of ctDNA at two or more sites after controlled disturbance might be used to constrain the location of source tumors. In this installment, many of the technical details for doing this will be examined.
Time Constants, Decay Curves, Differential Erosion, and Joint Densities
There are two principal processes which affect this model of these phenomena. One is the decay time or physiological clean-up time for ctDNA of interest in the blood. That time will be denoted 
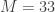

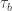
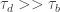
The technique also assumes that differential erosion is negligible. By this I mean that there are not substantial differences in the relative concentration of ctDNA depending upon the paths taken through the CVS. There are concentration differences based upon diffusion and flow, but it assumes there aren’t special processes along certain paths which attenuate ctDNA concentrations in addition.
In the model considered here, a unit contribution of ctDNA is made to the blood stream in an organ, here modelled as a nde in a network. In order to use differential localization, ctDNA needs to be sampled at sites before concentrations come to equilibrium throughout the body. That means in the clinical setting, samples of ctDNA need to be taken concurrently at two or more sites a few dozen heartbeats after a generating event, such as vigorous exercise. Localization depends upon two factors, both time dependent. One is, of course, the ctDNA being present at all. The second is the time dependent non-equilibrium contributions of differing paths to the concentration at a point of observation. As the observation time, 
In actuality, the contribution of ctDNA from a site after activity is probably going to continue for some time, separately from the decay time
Transition Matrix
Recall the schematic CVS model from Shandas course which was shown in the first installment:

Each node in this network is identified in this diagram by a number. There are 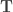





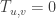







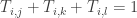
In general, long term equilibrium concentrations of material deposited in nodes of any such network after
In addition to the approximate nature of the Shandas network, in instances where flows split like this, the author made educated guesses regarding the proportion of flow leaving such a node for others. The reason why more care was not taken with this determination is that:
- The additional detail was not judged to be crucial for such this explanation of the technique.
- Proportions of flow vary from patient to patient.
- Proportions of flow vary from time to time within the same patient.
- The additional detail is available from the more comprehensive studies and models described in the first installment, such as in the material by Olufsen.
- Providing more details would suggest the long term stable equilibrium of such flow was all that mattered, or the expected value of such equilibria, and that is both untrue and misleading.
- A sensitivity analysis of the results of this installment to such variations will be presented in an upcoming installment.
Nevertheless, for the purposes of this description, it is assumed the transition matrix does faithfully represent the node to node flow allocations, and that, therefore, the equilibrium concentrations of any material deposited among the nodes after the time for CVS redistribution discussed just above is exceeded applies. It’s assumed that sampling of concentrations by node is arranged after such a time, and before appreciable ctDNA has decayed.
It’s presumed that material does not pool in the nodes. If it did, the entries 
So, what about
| FromNode | ToNode | Proportion |
|---|---|---|
| 33 | 1 | 1.0000 |
| 31 | 2 | 0.6667 |
| 1 | 3 | 1.0000 |
| 32 | 4 | 0.0625 |
| 15 | 5 | 0.5000 |
| 15 | 6 | 0.5000 |
| 18 | 7 | 0.5000 |
| 19 | 8 | 0.1250 |
| 22 | 8 | 1.0000 |
| 21 | 9 | 0.5000 |
| 21 | 10 | 0.5000 |
| 12 | 11 | 1.0000 |
| 26 | 12 | 0.2500 |
| 27 | 13 | 0.2000 |
| 27 | 14 | 0.8000 |
| 16 | 15 | 1.0000 |
| 17 | 16 | 0.2000 |
| 31 | 16 | 0.3333 |
| 32 | 17 | 0.9375 |
| 17 | 18 | 0.8000 |
| 18 | 19 | 0.5000 |
| 19 | 20 | 0.8750 |
| 20 | 21 | 0.1250 |
| 9 | 22 | 1.0000 |
| 10 | 22 | 1.0000 |
| 8 | 23 | 1.0000 |
| 24 | 23 | 1.0000 |
| 11 | 24 | 1.0000 |
| 25 | 24 | 1.0000 |
| 13 | 25 | 1.0000 |
| 14 | 25 | 1.0000 |
| 20 | 26 | 0.8750 |
| 26 | 27 | 0.7500 |
| 7 | 28 | 1.0000 |
| 23 | 28 | 1.0000 |
| 28 | 29 | 1.0000 |
| 30 | 29 | 1.0000 |
| 5 | 30 | 1.0000 |
| 6 | 30 | 1.0000 |
| 3 | 31 | 1.0000 |
| 2 | 32 | 1.0000 |
| 4 | 33 | 1.0000 |
| 29 | 33 | 1.0000 |
One Heartbeat
Note that if the relative proportions of a set of concentrations of materials are represented as a column vector 

Accordingly after the
and the analysis sketched in the first installment can be used to describe concentrations as 

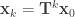
The steady-state or equilibrium concentration of any material can be described by a differential equation known as the diffusion equation, as described by G. Strang in his textbook Linear Algebra and Its Applications (2nd edition, 1980), sections 5.2-5.4.
Towards Tumor Localization
In particular, if one were to posit that a tumor was located in the
![\mathbf{x}_{k} = \mathbf{T}^{k} \left[0, 0, \dots, 1, \dots, 0 \right]^{\top}_{0}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D_%7Bk%7D+%3D+%5Cmathbf%7BT%7D%5E%7Bk%7D+%5Cleft%5B0%2C+0%2C+%5Cdots%2C+1%2C+%5Cdots%2C+0+%5Cright%5D%5E%7B%5Ctop%7D_%7B0%7D&bg=ffffff&fg=333333&s=0&c=20201002)
where there are 

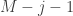

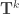
So What Does It Look Like? And About That Window of Opportunity …
If sampling is done too early, ctDNA would not be sufficiently circulated to obtain a good sample. If it is done too late, then equilibrium concentrations dominate, and it information about the original location of the tumor would be lost. It is best to see this this graphically. The following sequence of images show the relative concentrations of hypothetical ctDNA relative to a unit quantity deposited in one of the







Relative Concentrations
Since absolute concentrations don’t mean anything here because the original concentration of ctDNA is not known, what’s of diagnostic interest is the relative concentration of ctDNA at two sites. For illustration, relative concentrations at various sampling times were calculated for the ratio of the concentrations at node 14 to node 15, roughly, the legs to the arms, and at node 25 to node 14, roughly a pelvic vein to the legs. In the following displays the rows correspond to the location of the tumor. If the ratios differ between putative tumor sites, there is diagnostic power in the ratio. If they are comparable, discrimination is poor or none.
The following shows sampling times across the columns, in roughly, heartbeats, and locations of tumors in the rows. This display is the ratio of legs to arms.
| tumor site | R20 | R25 | R30 | R35 | R40 | R45 | R50 | R70 | R100 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Inf | 1.6276 | 1.8371 | 0.5326 | 0.753 | 1.353 | 0.675 | 0.852 | 0.980 |
| 2 | 0.0000 | 0.0000 | 2.0312 | 0.2274 | 1.378 | 1.349 | 1.555 | 1.058 | 0.976 |
| 3 | 72.0000 | 7.2187 | 2.2213 | 0.8340 | 1.153 | 0.626 | 0.976 | 1.016 | 0.973 |
| 4 | NaN | Inf | 1.6276 | 1.8371 | 0.533 | 0.753 | 1.353 | 1.216 | 1.018 |
| 5 | 0.0000 | 0.6667 | 1.3952 | 1.9287 | 0.414 | 0.914 | 1.353 | 1.126 | 1.021 |
| 6 | 0.0000 | 0.6667 | 1.3952 | 1.9287 | 0.414 | 0.914 | 1.353 | 1.126 | 1.021 |
| 7 | NaN | 8.0000 | 0.1008 | 1.2984 | 1.078 | 1.617 | 0.810 | 1.054 | 1.000 |
| 8 | 0.0000 | 0.0000 | 2.1333 | 0.5967 | 0.514 | 1.260 | 1.475 | 0.953 | 0.992 |
| 9 | NaN | NaN | Inf | 1.6276 | 1.837 | 0.533 | 0.753 | 1.052 | 0.967 |
| 10 | NaN | NaN | Inf | 1.6276 | 1.837 | 0.533 | 0.753 | 1.052 | 0.967 |
| 11 | NaN | 0.1250 | 72.0000 | 7.2187 | 2.221 | 0.834 | 1.153 | 0.899 | 0.992 |
| 12 | NaN | NaN | Inf | 1.6276 | 1.837 | 0.533 | 0.753 | 1.052 | 0.967 |
| 13 | NaN | 0.1250 | 72.0000 | 7.2187 | 2.221 | 0.834 | 1.153 | 0.899 | 0.992 |
| 14 | NaN | 0.1250 | 72.0000 | 7.2187 | 2.221 | 0.834 | 1.153 | 0.899 | 0.992 |
| 15 | 1.3333 | 2.4176 | 0.1116 | 0.9070 | 1.955 | 0.662 | 0.930 | 1.080 | 1.012 |
| 16 | 0.0625 | 0.6180 | 2.2635 | 0.3946 | 1.098 | 1.292 | 1.259 | 1.025 | 0.993 |
| 17 | NaN | Inf | 1.6276 | 1.8371 | 0.533 | 0.753 | 1.353 | 1.216 | 1.018 |
| 18 | 0.1250 | 72.0000 | 7.2187 | 2.2213 | 0.834 | 1.153 | 0.626 | 0.943 | 1.038 |
| 19 | NaN | 8.0000 | 0.1008 | 1.2984 | 1.078 | 1.617 | 0.810 | 1.054 | 1.000 |
| 20 | 0.0000 | 0.0000 | 0.0000 | 2.0312 | 0.227 | 1.378 | 1.349 | 0.881 | 1.028 |
| 21 | NaN | 1.3333 | 0.0625 | 0.1249 | 0.725 | 2.139 | 0.495 | 0.785 | 0.967 |
| 22 | NaN | 0.1250 | 72.0000 | 7.2187 | 2.221 | 0.834 | 1.153 | 0.899 | 0.992 |
| 23 | Inf | 0.9517 | 1.0379 | 0.0469 | 0.775 | 0.635 | 1.677 | 1.158 | 1.012 |
| 24 | Inf | 0.0000 | 0.6154 | 0.0554 | 1.881 | 0.308 | 1.429 | 1.104 | 1.002 |
| 25 | NaN | NaN | 8.0000 | 0.1008 | 1.298 | 1.078 | 1.617 | 1.042 | 0.952 |
| 26 | NaN | 1.3333 | 0.0625 | 0.1249 | 0.725 | 2.139 | 0.495 | 0.785 | 0.967 |
| 27 | NaN | NaN | Inf | 1.6276 | 1.837 | 0.533 | 0.753 | 1.052 | 0.967 |
| 28 | 0.0000 | 0.0000 | 0.6926 | 1.9688 | 0.729 | 1.284 | 1.154 | 0.972 | 1.028 |
| 29 | 0.0000 | 2.0156 | 0.1601 | 1.3671 | 1.412 | 1.591 | 0.725 | 0.994 | 0.992 |
| 30 | 0.1250 | 2.6182 | 3.6406 | 1.2681 | 0.824 | 1.510 | 0.581 | 0.893 | 1.018 |
| 31 | 8.0000 | 0.1008 | 1.2984 | 1.0779 | 1.617 | 0.810 | 1.331 | 0.963 | 0.998 |
| 32 | 1.3333 | 0.0625 | 0.1249 | 0.7248 | 2.139 | 0.495 | 1.007 | 1.093 | 1.017 |
| 33 | 0.0625 | 0.1249 | 0.7248 | 2.1387 | 0.495 | 1.007 | 1.011 | 0.957 | 1.010 |
This display is the ratio of pelvic to legs.
| tumor site | S20 | S25 | S30 | S35 | S40 | S45 | S50 | S70 | S100 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0556 | 0.0378 | 0.5840 | 3.8387 | 1.065 | 0.592 | 1.102 | 0.941 | 1.059 |
| 2 | Inf | Inf | 0.4927 | 1.4802 | 0.956 | 1.621 | 0.796 | 0.951 | 0.992 |
| 3 | 0.2500 | 3.6638 | 0.7708 | 0.3123 | 0.814 | 2.699 | 0.930 | 1.045 | 0.970 |
| 4 | Inf | 0.0556 | 0.0378 | 0.5840 | 3.839 | 1.065 | 0.592 | 0.855 | 0.991 |
| 5 | Inf | 3.0556 | 0.0756 | 0.5387 | 3.333 | 1.023 | 0.755 | 0.987 | 0.978 |
| 6 | Inf | 3.0556 | 0.0756 | 0.5387 | 3.333 | 1.023 | 0.755 | 0.987 | 0.978 |
| 7 | Inf | 0.5000 | 2.7070 | 0.9991 | 2.970 | 0.759 | 0.457 | 0.765 | 1.029 |
| 8 | NaN | Inf | 0.6270 | 0.7708 | 1.155 | 1.629 | 1.176 | 1.224 | 0.963 |
| 9 | NaN | Inf | 0.0556 | 0.0378 | 0.584 | 3.839 | 1.065 | 1.107 | 0.945 |
| 10 | NaN | Inf | 0.0556 | 0.0378 | 0.584 | 3.839 | 1.065 | 1.107 | 0.945 |
| 11 | NaN | 0.0000 | 0.2500 | 3.6638 | 0.771 | 0.312 | 0.814 | 1.005 | 1.066 |
| 12 | NaN | Inf | 0.0556 | 0.0378 | 0.584 | 3.839 | 1.065 | 1.107 | 0.945 |
| 13 | NaN | 0.0000 | 0.2500 | 3.6638 | 0.771 | 0.312 | 0.814 | 1.005 | 1.066 |
| 14 | NaN | 0.0000 | 0.2500 | 3.6638 | 0.771 | 0.312 | 0.814 | 1.005 | 1.066 |
| 15 | 0.0469 | 0.4909 | 9.4785 | 0.9625 | 0.726 | 1.070 | 0.980 | 0.900 | 1.001 |
| 16 | 16.0000 | 0.8426 | 0.9456 | 1.1454 | 0.705 | 1.413 | 1.097 | 1.029 | 0.987 |
| 17 | Inf | 0.0556 | 0.0378 | 0.5840 | 3.839 | 1.065 | 0.592 | 0.855 | 0.991 |
| 18 | 0.0000 | 0.2500 | 3.6638 | 0.7708 | 0.312 | 0.814 | 2.699 | 1.240 | 0.972 |
| 19 | Inf | 0.5000 | 2.7070 | 0.9991 | 2.970 | 0.759 | 0.457 | 0.765 | 1.029 |
| 20 | NaN | Inf | Inf | 0.4927 | 1.480 | 0.956 | 1.621 | 1.483 | 0.946 |
| 21 | NaN | 0.0000 | 0.0000 | 16.2500 | 0.932 | 0.489 | 1.246 | 0.859 | 1.094 |
| 22 | NaN | 0.0000 | 0.2500 | 3.6638 | 0.771 | 0.312 | 0.814 | 1.005 | 1.066 |
| 23 | 1.9091 | 0.0000 | 0.3924 | 12.8378 | 2.057 | 0.851 | 0.618 | 0.865 | 1.002 |
| 24 | 0.0000 | Inf | 3.5000 | 5.7070 | 0.564 | 1.973 | 0.908 | 0.937 | 0.993 |
| 25 | NaN | Inf | 0.5000 | 2.7070 | 0.999 | 2.970 | 0.759 | 0.954 | 0.986 |
| 26 | NaN | 0.0000 | 0.0000 | 16.2500 | 0.932 | 0.489 | 1.246 | 0.859 | 1.094 |
| 27 | NaN | Inf | 0.0556 | 0.0378 | 0.584 | 3.839 | 1.065 | 1.107 | 0.945 |
| 28 | Inf | Inf | 2.1063 | 0.3858 | 0.555 | 0.979 | 1.588 | 1.267 | 0.957 |
| 29 | Inf | 0.4961 | 2.1852 | 0.9673 | 1.556 | 0.790 | 0.745 | 0.837 | 1.029 |
| 30 | 0.0000 | 0.1250 | 3.6323 | 1.4639 | 0.364 | 0.647 | 2.279 | 1.134 | 1.004 |
| 31 | 0.5000 | 2.7070 | 0.9991 | 2.9703 | 0.759 | 0.457 | 0.808 | 0.993 | 1.032 |
| 32 | 0.0000 | 0.0000 | 16.2500 | 0.9320 | 0.489 | 1.246 | 1.248 | 0.962 | 0.991 |
| 33 | 0.0000 | 16.2500 | 0.9320 | 0.4892 | 1.246 | 1.248 | 1.344 | 1.247 | 0.963 |
It’s clear that the most discrimination appears at sampling times 30 through 50. Accordingly, in this example, at the 40 tick point, a legs to arms concentration ratio of 0.5 suggests node 20, or a liver source. In practice, these ratios will have highest density intervals (“HDI“) which may overlap and, so, there may be ambiguity as to source. Such ambiguity might be resolved using other clinical knowledge, repeating the sampling slightly later, or using another site to develop additional ratios.
Sampling Plans
In addition to discriminating among locations, the same scheme can be used to plan detection. For instance, if there is a strong prior on certain locations for a tumor, this prior in combination with these kinds of studies can be used to plan where and when samples can be taken.
Revising Use in a Clinical Setting
Recall the proposed use in a clinical setting:
- Patient is identified with a tumor having specific ctDNA.
- Patient undergoes exercise or vigorous activity as tolerated.
- Patient returns to a resting posture.
- Blood samples are quickly drawn from members which study suggests will best constrain location of tumor. Roughly speaking, and depending upon further details from models of the CVS, samples should be taken without a minute of stopping exercise.
- Relative concentrations of ctDNA are obtained from blood samples.
- Relative concentrations are combined with results from present study and CVS model to estimate probable location of sources.
- As needed, additional samples are drawn to further constrain location of tumor.
- Relative concentrations of ctDNA are obtained from these.
- Bayes Rule is used to update the estimate of location of the tumor.
- Imaging is applied to locations to confirm and further specify locations.
Note that the relaxation time for ctDNA concentrations depends upon finer details of the CVS model, and upon a sensitivity analysis of this calculation to variations in the network transition matrix,
The final installment will look at extensions, including how to combine two of these ratio measurements in an updated, Bayesian estimate of tumor location, and also how tracking these ratios over time might improve accuracy by using a state-space filter.





Pingback: On differential localization of tumors using relative concentrations of ctDNA. Part 1. | Hypergeometric