
This post could also be subtitled “Residual deviance isn’t the whole story.”
My favorite book on logistic regression is by Dr Joseph Hilbe, Logistic Regression Models, CRC Press, 2009, Chapman & Hill. It is a solidly frequentist text, but its discussion of models and rich examples make that besides the point. Except in one case. In Section 15.2.1, Professor Hilbe writes:
When exact methods fail while using LogXact or SAS as a result of memory limitations, it is recommended that estimation be attempted using Monte Carlo sampling methods. There are two such methods employed by the software: the Direct Monte Carlo sampling method of Mehta et al. (2000) and the Markov Chain Monte Carlo (MCMC) sampling method, which is based upon the Gibbs sampling algorithm proposed by Forster et al. (1996). However, Mehta et al. (2000) demonstrated that the MCMC method can lead to incorrect results and recommend that it only be used when all other methods fail. We suggest that it not be used even in those circumstances, and that there are methods not based on Monte Carlo sampling that can be used to approximate exact statistical results. We discuss these methods in the two next sections.
Now, strictly speaking, Professor Hilbe is apparently referring to capabilities in LogXact or SAS or both, not to MCMC methods everywhere. I am not familiar with these features of LogXact or SAS, so I cannot speak to that. But this was published in 2009, and a good many methods for generalized linear models (“GLMs”) which do successfully use MCMC, even for binomial logistic regression. Some of them do not use Gibbs samplers and it seems that steering students of the problem away from these methods under any circumstances without this qualification is overdone.
There should also be a proper separation of concerns here. One the one hand there is binomial logistic regression, whose shoals present threats to general algorithms for GLMs whose non-linear optimizers, often based upon Newton methods, can founder. Separation is one such problem. It is common for authors of functions in packages intended to solve logistic regression to test them on such cases. The other is the viability of Markov Chain Monte Carlo (“MCMC”) methods, such as those criticized by Hilbe and Mehta, et al. I had a quick look at results based upon:
J. J. Forster, J.W. McDonald, P. W. F. Smith, “Monte Carlo exact conditional tests for log-linear and logistic models”, Journal of the Royal Statistical Society B, 1996, 58, 445-453 (*).
Specifically, I consulted:
D. Zamar, B. McNeny, J. Graham, “elrm: Software implementing exact-like inference for logistic regression models“, Journal of Statistical Software, October 2007, 21(3).
They report that the Forster et al. (1996) technique cited by Hilbe and Mehta, et al. (2000) is indeed a Gibbs sampler, but that
J. J. Forster, J. W. McDonald, P. W. F. Smith, “Markov Chain Monte Carlo exact inference for Binomial and Multinomial logistic regression models”, Statistics and Computing, 2003, 13, 169-177.
uses a general MCMC algorithm, not merely a Gibbs sampler, which Zamar, McNeny, and Graham implement and report upon.
While a comprehensive evaluation of these techniques is more than I presently have time, I decided to take the specific example Mehta, et al. (2000) used to claim the inferiority of the MCMC technique from their paper, namely, their small Table 1 dataset, reproduced below, and attempt to solve it using various packages, comparing results. That dataset is:
| group.id | response | size | var.1 | var.2 |
|---|---|---|---|---|
| 1 | 4 | 4 | 0 | 1 |
| 2 | 0 | 2 | 2 | 2 |
| 3 | 0 | 2 | 3 | 3 |
| 4 | 0 | 2 | 5 | 4 |
| 5 | 0 | 2 | 7 | 5 |
| 6 | 1 | 2 | 17 | 6 |
The methods and packages I tried were the BayesGLM function from the Gelman, Hill, Su, Yajima, Grazia, Kerman, Zheng, and Dorie arm package, the MCMClogit function from the MCMCpack package by Martin, Quinn, and Park, the glmrob function from the robustbase package by Maechler, and the elrm function from the elrm package by Zamar, Graham, and McNeny. Note both the MCMClogit function assumes a Bernoulli not a Binomial model for the data, and, so, for these cases the above table needs to be expanded to Binomial instances. This can be done using an R snippet,
Table1.expanded<- matrix(0, nrow=0, ncol=4)
for (k in (1:nrow(Table1)))
{
if (0 < Table1[k,2])
{
for (j in (1:Table1[k,2]))
{
Table1.expanded<- rbind(Table1.expanded, c(Table1[k,1], 1, Table1[k,4], Table1[k,5]))
}
}
if (Table1[k,2]<Table1[k,3])
{
for (j in ((1+Table1[k,2]):Table1[k,3]))
{
Table1.expanded<- rbind(Table1.expanded, c(Table1[k,1], 0, Table1[k,4], Table1[k,5]))
}
}
}
colnames(Table1.expanded)<- c("group.id", "response", "var.1", "var.2")
BernoulliTable1.frame<- as.data.frame(Table1.expanded, stringsAsFactors=FALSE)
This produces the revised data table for these functions:
| group.id | response | var.1 | var.2 |
|---|---|---|---|
| 1 | 1 | 0 | 1 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 0 | 1 |
| 2 | 0 | 2 | 2 |
| 2 | 0 | 2 | 2 |
| 3 | 0 | 3 | 3 |
| 3 | 0 | 3 | 3 |
| 4 | 0 | 5 | 4 |
| 4 | 0 | 5 | 4 |
| 5 | 0 | 7 | 5 |
| 5 | 0 | 7 | 5 |
| 6 | 1 | 17 | 6 |
| 6 | 0 | 17 | 6 |
Robust GLM
First of all, the “robust” glmrob was not. Using a method of “Mqle”, it consistently reported:
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
Error in solve.default(crossprod(X, DiagB * X)/nobs, EEq) :
system is computationally singular: reciprocal condition number = 5.84949e-18
I could not get the method “BY” to work because when I tried to pass success counts and fail counts in a response variable, as recommended for glm and the Binomial family, glmrob did not know what to do with this. According to the documentation I read, this was needed. According to R‘s family function description:
For the binomial and quasibinomial families the response can be specified in one of three ways:
(1) As a factor: ‘success’ is interpreted as the factor not having the first level (and hence usually of having the second level).
(2) As a numerical vector with values between 0 and 1, interpreted as the proportion of successful cases (with the total number of cases given by the weights).
(3) As a two-column integer matrix: the first column gives the number of successes and the second the number of failures.
Yet glmrob complains when “(3)” is used.
Out-of-the-Box GLM
Second, the straight-out-of-the-box built-in glm works, but does a bad job of it:
M1<- glm (response ~ var.1 + var.2, family=binomial(link="logit"), data=Table1.frame, weights=Table1.weights)
producing:
Classical GLM Logistic Regression
glm(formula = response ~ var.1 + var.2, family = binomial(link = "logit"),
data = Table1.frame, weights = Table1.weights)
| coef.est | coef.se | |
|---|---|---|
| (Intercept) | 132.91 | 214462.33 |
| var.1 | 30.53 | 47968.87 |
| var.2 | -108.64 | 170869.81 |
---
n = 6, k = 3
residual deviance = 0.0, null deviance = 15.5 (difference = 15.5)
Residuals: 1 2 3 4 5 6
1.0000006533e+00 -1.0000000001e+00 -1.0000000000e+00 -1.0000000000e+00 -1.0000000000e+00 -1.1368683772e-13
Just look at those standard errors! Yet the residual deviance is zero, which looks more to me like a failure of calculation than anything accurate.
arm Package BayesGLM
Now the BayesGLM produced the following estimates:
| Cauchy prior scale | DF value | residual deviance obtained | var.1 estimate | var.1 s.e. | var.2 estimate | var.2 s.e. | |
|---|---|---|---|---|---|---|---|
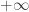 |
|
0.6 | 3.76 | 10.34 | -13.53 | 7.89 | |
| 2.5 (default) | |
10.9 | 0.11 | 0.14 | -0.71 | 0.44 | |
| 2.5 | 1 | 10.9 | 0.11 | 0.14 | -0.71 | 0.44 | |
| 2.5 | 7 | 10.9 | 0.11 | 0.14 | -0.71 | 0.44 | |
| 5.0 | |
7.9 | 0.35 | 0.22 | -1.50 | 0.73 |
Those standard errors look pretty good, excepting the first and last rows, where the deterioration is expected.
MCMCpack package MCMClogit
This function took a lot of work in order to produce anything reasonable with this problem. Worse, even at 1.5 million MCMC steps and a burn-in of 250,000 the standard errors are poor. Ironically, the deviance is better than the arm results, suggesting to me that the problem with these large coefficient results is overfitting. However, I have not inspected the algorithm MCMClogit uses. I am a little surprised, since it is possible to tune this interface directly for a logistic regression, rather than use a general-purpose interface for GLMs as the other packages do.
A user-defined Cauchy prior was used for this routine, namely,
logpriorfun <- function(beta, location, scale)
{
sum(dcauchy(beta, location, scale, log=TRUE))
}
with the call
posterior<- MCMClogit(response ~ var.1 + var.2, burnin=250000, mcmc=1500000, thin=10, tune=0.0001, verbose=0, seed=wonkyRandom,
beta.start=rnorm(3, 0, 0.1), data=BernoulliTable1.frame, user.prior.density=logpriorfun,
logfun=TRUE, location=0, scale=2.5, marginal.likelihood="Laplace")
Remember this routine demands a Bernoulli model. The runs look okay:

| Cauchy prior scale | Tuning Parameter | Metropolis acceptance rate | residual deviance obtained | var.1 estimate | var.1 s.e. | var.2 estimate | var.2 s.e. | |
|---|---|---|---|---|---|---|---|---|
| 2.5 | 0.0001 | 0.467 | 8.37 | 1.07 | 0.008 | -4.27 | 0.028 |
The standard errors have, of course, been corrected for MCMC effective size, which are
| (kind) | (Intercept) | var.1 | var.2 |
|---|---|---|---|
| effective size | 22792.5 | 18774.3 | 19340.3 |
| standard deviations | 4.900 | 1.088 | 3.873 |
Thus, in this case, the bias-finding for MCMC logstic regression algorithms appears to be correct. The acceptance rate is a little high, and there were settings of the turning parameter which knocked acceptance lower, but it is very sensitive and does not produce consistent results, at least not with the random initialization for 
elrm package elrm
This is the 2003 re-implementation of MCMC for logistic regression developed by Forster, McDonald, and Smith, as implemented by
Zamar, McNeny, and Graham. It’s an odd duck because, despite using a constructed Markov Chain, it reports p-values rather than, say, credible intervals. In doing so, however, it offers a specific comparison with the complaints of Hilbe and Mehta, et al., who observed that their runs of the earlier Forster, McDonald, and Smith Gibbs sampler always produced p-values very nearly unity. No deviances are produced by this routine, and the coefficients returned do not include the Intercept, so I could not calculate residuals myself.
| #burn-in steps | #MCMC steps | joint p-value | var.1 estimate | var.1 p-value | var.1 p-value s.e. | var.2 estimate | var.2 p-value | var.2 p-value s.e. |
|---|---|---|---|---|---|---|---|---|
| 50,000 | 500,000 | 0.00994 | 0.396 | 0.034 | 0.004 | -0.771 | 0.021 | 0.002 |
| 25,000 | 250,000 | 0.00658 | 0.388 | 0.036 | 0.014 | -0.768 | 0.021 | 0.006 |
Odd duck indeed. While the estimates fall more of less in line with results of BayesGLM from arm, the joint p-value decreases, separated by almost 7 times the pooled standard error of 0.00049.
| #MCMC steps | joint p-value s.e. | effective number of steps for joint p-value |
|---|---|---|
| 500,000 | 0.00025 | 450,000 |
| 250,000 | 0.00042 | 225,000 |
The estimate for the first variable is higher than than produced by BayesGLM. The standard errors from the elrm chains for the two variables, corrected for effective size are 0.05 and 0.017. The pooled standard error for that first variable is thus about 0.15 and, so, the two estimates for the first variable are separated by under two pooled standard errors, which is consistent if not plausible.
Code, Trace, and Consensus
The R code to reproduce these results along with a trace of the execution are available in a tarball. Note that the call to the glmrob is conditionally executed, and the default is off, because it otherwise stops the script.
My consensus is that I’d trust arm‘s BayesGLM for general work, and perhaps run elrm as a cross-check.
(*) I did not consult the original paper because I have no access to the Journal of the Royal Statistical Society.





Pingback: Less evidence for a global warming hiatus | Hypergeometric
Hi Thao Tran! Thanks for your comment and question.
Before moving on to algorithms and their problems, I need to understand your methods and rationale. In particular, the idea of estimating “prediction accuracy” in the manner proposed is unconventional for these techniques. I’m not sure, unless you have other domain specific justifications, that this cross validation technique will get you what you want, or if averaging prediction accuracy has any meaning. There is a perspective, for example, that if anything shy of the entire dataset is used there is greater uncertainty in any of the parameters, something which cannot be made up for by an arbitrary bootstrapped validation.
I would, instead, recommend doing diagnostics on the result of bayesglm, typically looking at the posterior distribution. How to do that is sketched here. Recall, the result of bayesglm is not the posterior, but an empirical function fit to a lobe of the posterior which is presumed to be the correct lobe. (See the “Detail” section of the documentation.) Sections 15.6 and 16.4 of Gelman, Carlin, Stern, Dunson, Vehtari, and Rubin (Bayesian Data Analysis, 3rd edition, BDA3) argue for exploiting structure in problems as well as interpreting and presenting results as an analysis of variance (ANOVA) plot.
If you’d like to check the robustness of a result, the standard practice is to try combinations of different initialization points and different but reasonable priors. If your result is solid, they all should converge to the same place. If they don’t, either the initialization is too far off, or your posterior may be multimodal, with the modes being comparable.
With peculiar datasets it is possible you may need to write your own solver rather than lean on an existing package. Gelman, et al talk about how that might be done. For reasons of reliability I tend not to do that for publication quality work, but I will formulate the problem in a couple of different ways and see that I get the same result. In particular, if doing a logistic regression, I’d look at a probit regression model as described, for instance, in 16.1 of BDA3 or even the more robust t-link suggested in section 17.2 of the same. (Gelman and authors of arm do something like that there, if I recall properly.) I send you there, and places like chapter 7 by Siddhartha Chib in Generalized Linear Models: A Bayesian Perspective because your problem may be suffering from overdispersion or correlation, or a couple of other ills.
Probit regression is also available via bayesglm in arm or as the realization of Chib’s algorithm as MCMCprobit in the MCMCpack package.
Finally, to your separation problems, these are discussed in detail here and here, and in fact Gelman, et al describe the solution they built into the bayesglm function of arm. I suspect you need to adjust your parameters, prior, or model, but without seeing what these are and the data, I can’t advise. I also see your receiving this error as a problem which needs to be solved, or shown, using another technique and approach like probit regression, to not affect the answer.
Finally, Rainey has recently discussed the problem and urges pursuit of an informative prior from the problem space. I second his recommendation, except I’d say get three reasonable ones and try them all, in addition to the Gelman, et al Cauchy. If in addition the probit agrees with the result of the logistic regression, I’d say you are on pretty solid ground.
Hi.
I have a question regarding the bayesglm() in arm package and hope to have your opinion.
Basically I have logistic regression, which I put it in a loop in order to get averaged prediction accuracy results over 100 times: I have 95 data points which are randomly divided into train set (80% data points) and test set (20% data points) 100 times. I then run logistic regression on the train set, use the fitted model to predict on the test set, calculate the misclassification error and average over them.
However, when running glm(), I got the warning message: “fitted probabilities numerically 0 or 1 occurred” which I understand that I have encountered the separation problem in logistic. This might be due to the random process which generates my train set as when I use glm() in the whole data set, it does not produce any warning like that.
So I decided to continue with bayesglm() in order to get good standard deviation of parameter estimates and obtain more accurate prediction. However, when running this function, I still get about 50 warnings: “fitted probabilities numerically 0 or 1 occurred”.
My question is:
Does this warning “fitted probabilities numerically 0 or 1 occurred” when using bayesglm() really a problem??? I mean the prediction based on the fitted logistic regression can be reliable or not? Or it is just a warning saying that there is possible problem of separation, but in the end, bayesglm() can handle it well and the produced results are still sufficient.