
Stable distributions or Lévy 
![\alpha \in (0, 2]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%280%2C+2%5D&bg=ffffff&fg=333333&s=0&c=20201002)
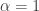

They are also of interest as test cases for Bayesian inference, especially for algorithms doing approximate Bayesian computation (“ABC”). My interest here is to use such creatures to illustrate that even if a natural process is governed by them, it does not elude analysis, study, or engineering. In particular, diffusion processes such as those encountered in weather and climate science have distributions which are contained in the set of
That a phenomenon’s observables exhibit a statistical distribution in however many dimensions lacks moments or means or variance does not stop its study or characterization. It may make certain questions regarding the phenomenon nonsensical or, at least, not having an answer. Specifically, questions which demand the existence of, say, an average regarding them simply cannot be answered, not because of lack of knowledge regarding the phenomenon, but because of its nature. To persist asking these is failing to acknowledge that nature. It is also inconsistent to claim that such phenomena have these distributions and proceed to conduct statistical tests on observables which assume, say, that such moments exist for them. Most egregious in this regard are use of results from significance tests with interpretations that these somehow represent return times of some underlying event.
This is not surprising. In fact, to me, this has long been part of the Bayesian program. For few actual, empirical probability densities are readily characterized in terms of the classical forms. These are approximations to empirical densities. It is, therefore, better to deal with the actual densities if they can be, rather than force-fitting them into standard forms and risk model specification or so-called Type III errors. Much of the recent work on Bayesian computational methods, especially on Bayesian hierarchical models, has been pursued in exactly this spirit.
The byproduct of any Bayesian analysis are a set of marginal densities corresponding to their posterior distributions for the model’s parameters. A Bayesian analysis done to predict future ocean heat content, for example, would announce, when complete, a density for each spatial point at a moment in time. One could, operationally, calculate a mean of these densities, in the same way the mean of an N-point draw from a Cauchy distribution can be calculated. But, to the Bayesian, while that is sometimes appropriate, in general the smallest description of such an analysis are these posteriors. A Bayesian would say they suffice for all questions of interest. Suppose, for instance, a risk of a fishery someplace being decimated because of such temperatures is to be calculated. Presumably there’s a hazard function which maps temperatures into fish mortality. To calculate the risk, then, the procedure is to select the densities for the points in the area of interest, and to do the integration, probably numeric, of the densities derived from the Bayesian analysis with the hazard function to calculate the risk in that area. It doesn’t matter if the moments of these densities are missing.
Objections that we cannot make predictions of such risk because, say, diffusion processes exhibit wonky statistical properties is, in my opinion, just a convoluted way of misleading the public which does not know about diffusion processes, Lévy distributions, and the like. I have remarked on roughly the same kind of ploy with respect to chaos theory elsewhere here.




