
I. Introduction.
It’s time to fulfill the promise made in “Phase plane plots of COVID-19 deaths“, a blog post from 2nd May 2020, and produce the same with uncertainty clouds about the functional trajectories(*). To begin, here are some assumptions I’ve made:
- The data in a death series are dependent. So, as in autoregressive models, the current prediction of number of deaths is dependent upon the previous number of deaths, so
.
- There is “noise” in observations, and possibly in estimates of deaths. This can be due to a large number of different policies being adopted for when deaths are reported, or it can be because deaths are not being reported at the time they actually occurred, but later. This is typically managed by smoothing of some kind and this analysis, like many others, is no different. Here, however, I’ll be using smoothing splines and, in particular, penalized smoothing splines.
- The noise variability may be heteroscedastic, meaning that there’s no reason to believe the variability at time
is the same as variability at time
, even if
. I’m planning to assume homoscedasticity in one part of the analysis, and then I’ll assume heteroscedasticity in another.
- The best estimate of actual deaths is obtainable through the data, even if the best estimate may be latent and need to be estimated after filtering. I do not use data that count excess deaths, as a rule. However, there may be some county or state included in the data which has included assumed deaths due to COVID-19.
- The estimator for the number of deaths ought, too, to estimate the rate of change in number of deaths, and the acceleration, or rate of change in rate of change in number of deaths at the same time.
- The estimator for the number of deaths and its first two derivatives ought to account for the observations being counts, not continuous measures. While the biggest series counts are quite large, they are still counts, not continuous measures. Nevertheless, robust analysis of such series generally means centering and scaling the series, so, while its shape is preserved, it looks, for all appearances as if it actually is a continuous measure. I treat these as such. If these are to brought back to the original context, this can be achieved by reversing the transformation.
Setting aside the peek ahead to smoothing splines for a moment, a standard approach to dealing with these kind of data is dynamic linear modeling, otherwise known as state-space models. It also suggests using software to estimate the time-varying magnitude of noises, and then extracting that to form the uncertainties in rates and rates of change in rates.
What does that mean, precisely? And is this standard approach the best approach or even a good approach? And how should that be judged?
Let 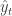
![\hat{y}_{t} = \left[\begin{array}{c}1 \\ 0 \\ 0 \end{array}\right] \mathbf{x}_{t} + \mathbf{\mathcal{N}}(0, \sigma_{y}^{2})](https://s0.wp.com/latex.php?latex=%5Chat%7By%7D_%7Bt%7D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D1+%5C%5C+0+%5C%5C+0+%5Cend%7Barray%7D%5Cright%5D+%5Cmathbf%7Bx%7D_%7Bt%7D+%2B+%5Cmathbf%7B%5Cmathcal%7BN%7D%7D%280%2C+%5Csigma_%7By%7D%5E%7B2%7D%29&bg=ffffff&fg=333333&s=1&c=20201002)
![\mathbf{x}_{t+1} = \left[\begin{array}{ccc}1 & 1 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 0 \end{array}\right] \mathbf{x}_{t} + \mathbf{\mathcal{N}}(\mathbf{0}_{3}, \boldsymbol\Sigma_{\mathbf{x}})](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D_%7Bt%2B1%7D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7D1+%26+1+%26+0+%5C%5C+0+%26+1+%26+1+%5C%5C+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D+%5Cmathbf%7Bx%7D_%7Bt%7D+%2B+%5Cmathbf%7B%5Cmathcal%7BN%7D%7D%28%5Cmathbf%7B0%7D_%7B3%7D%2C+%5Cboldsymbol%5CSigma_%7B%5Cmathbf%7Bx%7D%7D%29&bg=ffffff&fg=333333&s=1&c=20201002)
Here 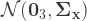

Expanding the definition of 
![\left[\begin{array}{c} x_{t+1} \\ \dot{x}_{t+1} \\ \ddot{x}_{t+1} \end{array} \right] = \left[\begin{array}{ccc}1 & 1 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 0 \end{array}\right] \left[\begin{array}{c} x_{t} \\ \dot{x}_{t} \\ \ddot{x}_{t} \end{array} \right] + \mathbf{\mathcal{N}}(\mathbf{0}_{3}, \boldsymbol\Sigma_{\mathbf{x}})](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+x_%7Bt%2B1%7D+%5C%5C+%5Cdot%7Bx%7D_%7Bt%2B1%7D+%5C%5C+%5Cddot%7Bx%7D_%7Bt%2B1%7D+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7D1+%26+1+%26+0+%5C%5C+0+%26+1+%26+1+%5C%5C+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+x_%7Bt%7D+%5C%5C+%5Cdot%7Bx%7D_%7Bt%7D+%5C%5C+%5Cddot%7Bx%7D_%7Bt%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cmathbf%7B%5Cmathcal%7BN%7D%7D%28%5Cmathbf%7B0%7D_%7B3%7D%2C+%5Cboldsymbol%5CSigma_%7B%5Cmathbf%7Bx%7D%7D%29&bg=ffffff&fg=333333&s=1&c=20201002)
The idea is to estimate the state components 
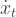

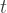
I used this approach in previous work. Unfortunately, good prediction intervals are not available using the dlm package. It does have a 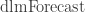
As another qualification or criticism, note it is difficult to deal with heteroscedasticity with such a model. Typically, estimates of errors in measurement need to be made independently and fed in as inputs.
So, instead of this approach, I’ve turned to a non-parametric, non-mechanistic way of estimating the latent curve of deaths and the first two derivatives needed to describe the series in the phase plane: Using penalized splines as before, but generalized to techniques which estimate uncertainties in them, whether they are used to spline signal or its derivatives. Specifically, I’m calculating prediction intervals for fits and for derivatives. The primary tool is the bootstrap technique for developing non-parametric prediction intervals, one described in section 3.1 of Denham’s paper:
M. C. Denham, "Prediction intervals in partial least squares", (1997), Journal of Chemometrics, 11(1), 39-52.
Actually, a later paper by Denham,
M. C. Denham, "Choosing the number of factors in partial least squares regression: estimating and minimizing the mean squared error of prediction", (2000), Journal of Chemometrics, 14(4), 351-361.
reveals the idea is from Efron and Tirshirani,
B. Efron, R. J. Tibshirani, An Introduction to the Bootstrap, 1993, Chapman & Hall, problem 25.8, 390-391.
That algorithm is also described in the documentation for the 
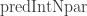
Also, as before, spline regression models and their predictions are done using the R pspline package.
(*) In addition to reading and studying since May, articles about the pandemic, articles about other areas of statistics, and regarding 100% clean, renewable energy plans, as long as my unemployment compensation continued, I was aggressively looking for work. That has not worked out, and my unemployment compensation is exhausted. So I’m semi-retired now, subsisting on Social Security, a modest pension, and with the support of my wife, Claire. If something interesting comes ’round, I’ll have a serious look at it. But meanwhile, here I am.
(**) A. C. Harvey, Forecasting, structural time series models and the Kalman filter, 1989, Cambridge University Press, 4.6, "Prediction", page 223.
(***) Very recently Feroze used (such) Bayesian structural time series models to forecast COVID-19 trends for cases, deaths, and recoveries, as documented in
N. Feroze, "Forecasting the patterns of COVID-19 and causal impacts of lockdown in top ten affected countries using Bayesian structural time series models", Chaos, Solitons and Fractals (2020).
Unfortunately, Feroze does not provide the specification of the models used in the bsts R or the settings for determination of causal impact of measures taken via the CausalImpact package. Accordingly, it is difficult to comment.
II. Estimating uncertainties.
Prediction intervals are estimated by bootstrapping residuals, generating predictions from a baseline perturbed prediction, and then using the non-parametric technique for estimating prediction intervals for each point in a time series. That is, and specifically,
- Fit a smoothing spline to the entire time series,
, one having a length
. Use generalized cross validation to estimate the smoothing parameter. Obtain a predicted smoothed series
from this spline regression.
- Calculate residuals
.
- Repeating through step 5
times, bootstrap
obtaining
.
- Calculate
.
- Fit a smoothing spline to
and predict
for the
time this is done.
- For each
, over all
instances of bootstrapped predictions, use non-parametric estimation of a prediction interval for time point
.
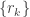
Since observational data on first and second derivatives are not available as given, the companion series of first and second derivatives are obtained by simple differencing and then applying a smoothing spline to those. The same procedure is used to obtained prediction intervals on first and second derivatives, substituting 

III. Where the code lives.
The code and datasets used to produce these figures resides in this Google Drive folder.
IV. How to Display Uncertainties.
After experimenting, I decided that phase plane plots having variable widths or decorations along the trace would be the best way to convey uncertainty. The key observation is that uncertainty in one of the dimensions can be numerically much larger than the other, and that the plot’s aspect ratio can distort these relationships. I decided that an error bar attached to the trace or path indicated by the data would be appropriate, with the bar having an orientation which was consistent with the implied slope of the vertical error over the horizontal error, and a length proportional to the length of their vectorial sum. Also, for reasons of symmetry, such bars would extend both above and below the path having these errors.

I examined using variable-width lines as a part of preliminary experiments. These are in fact supported by base R, but their application is not at all obvious. I did not want my code here to burden readers with mastering grid or ggplot2. I also examined the possibility of using TikZ via tikzDevice. In fact, TikZ can do this:

(Hat tip to matheburg.)
The corresponding code is:
\documentclass{article}
\usepackage{pgfplots}
\begin{document}
\begin{tikzpicture}[scale=2.5]
\begin{axis}[width=7cm, height=7cm, xmin=-1.05,
xmax=1.05, axis lines=none, view={0}{25}]
\foreach \x in {0,0.5,...,12.0}
{\edef\temp{\noexpand\addplot3[blue, line width=1+\x/2 pt,
domain=\x:\x+0.5,samples y=0]
( { cos( deg(x) ) }, { sin( deg(x) ) }, { x } );
} \temp }
\draw[>=latex,->] (105,100,10) -- (105,100,180);
\node at (95,90,178) { $z$ };
\end{axis}
\end{tikzpicture}
\end{document}
But, again, do I want people to master TikZ?
Accordingly I chose to keep within R, and devise a means of portraying these uncertainties using its plotting facilities. The decision was ultimately based upon the need to depict both vertical and horizontal errors at the same time, something which simply varying a line width could not portray.
V. Examples of Phase Plane Plots for COVID-19 Deaths.
I chose to depict uncertainties as ellipses with axes parallel to the two axes in question. So, for instance, if a plot of rate of deaths versus counts of deaths is shown, the horizontal span of the ellipse corresponds to the x-axis rate of deaths prediction interval, and the vertical corresponds to the uncertainty in the number of deaths. Consider, for example, that plot for New York State in the period of study, 13th March 2020 through 16th May 2020:

In all these instances simply click on the image to see a larger version … It’ll pop out into a separate window tab in your browser.
The count of deaths is monotonic so the trend is upwards, and this plot shows the variation in rates of death. Here’s the cumulative deaths over time for the same period:

Note that this kind of trend is pretty universal, so won’t be shown for many of the examples. It is logistic-like, not really exponential. Note that in this case — and in some of the others — there’s an anomaly on the 16th, with rates and counts being zero. This is probably due to incomplete counting on the 16th but could be for other reasons. It actually appears in the data.
Finally, for New York State, here’s the phase-plane plot sought:

The uncertainty envelopes in all cases, whether phase plane or counts versus rates are taken as the 0.667 prediction interval.
There are similar results from Massachusetts:


What’s gratifying is that the phase plane behavior appears real based upon the prediction uncertainties. As will be shown later, this isn’t always the case. Why there might be differences will be discussed in the summary.
Here’s the count versus rates for the United States as a whole:

And it’s phase plane plot also shows separation of the orbits:

although it’s not as clean as for Massachusetts or New York State.
Showing a case where the separation is not at all clear, consider the phase plane plot for Florida:

Apparently the rates for Florida vary widely:

Tennessee provides an intermediate case in its phase-plane plot:

Moving on to other countries, some of the data were quirky at best. There was something about China’s reporting, for instance, that causes singularities in the smoothing spline model builder. I did not investigate, since I’m less interested in any particular country and, one, what patterns reveal overall, and, two, how well these prediction interval methods for phase plane depictions work.
Here’s the phase plane for Switzerland:

Note it suffers an anomaly in the reporting for 16th May 2020 as did New York State.
The counts versus rates for Switzerland is:

Finally, here is the UK’s death counts versus rates of deaths:

VI. Summary.
Phase plane plots with prediction intervals were successfully constructed based upon death counts data from COVID-19 for several U.S. states and a number of countries. Some of the prediction intervals, such as those for Florida, are large and offer doubt regarding the meaning and interpretation of the phase plane depictions of rates of deaths and accelerations. But some states have reasonable prediction intervals.
It’s interesting to speculate why the differences. It’s possible there was inconsistency in reporting rates, so these mask the variation in the underlying deaths due to disease. If so, that would suggest wide prediction intervals may be an index of data from specific sources being poorly compiled, and so might provide a way of weighting them when being used for other studies. Certainly the consistency with which deaths were reported from New York State and Massachusetts allowed more confidence to be had in the reality of the phase plane orbits. Indeed, with that, these suggest the health governance of these states were tracking cases and taking measures, resulting in deaths and their rates exhibiting control system-like limit cycles.
It’s also interesting that this exercise took a great deal of effort and time, with about a dozen different means of estimating prediction intervals being tried, most in futility. I say “futility” not because prediction interval estimates were not produced but that, even in the cases of New York State and Massachusetts they were so wide to suggest the phase plane plots were meaningless. I was disappointed when split conformal inference prediction via its function 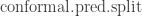
J. Lei, M. G’Sell, A. Rinaldo, R. J. Tibshirani, and Larry Wasserman, "Distribution-free predictive inference for regression", Journal of the American Statistical Association 113(523) (2018): 1094-1111.
G. Shafer, Glenn, V. Vovk, "A tutorial on conformal prediction", Journal of Machine Learning Research 9, March (2008): 371-421.
This may be because these time series data are just hard with which to deal, with many blemishes. However, there’s a caution there, because non-parametric means like conformal predictive inference, while they may give up statistical power, are in turn supposed to be robust against such blemishes.
In the end, phase planes and notions from dynamical systems and functional data analysis continue to be useful concepts and offer analytical tools for dealing with important data sets. It was great to see the venerable smoothing spline come out ahead of many other techniques, including some statistical learning approaches.




